OpenVINO™ Workflow Consolidation Tool
Speed up, streamline, and verify deep learning inference
The OpenVINO™ Workflow Consolidation Tool (OWCT) (available from the QTS App Center) is a deep learning tool for converting trained models into an inference service accelerated by the Intel® Distribution of OpenVINO™ Toolkit (Open Visual Inference and Neural Network Optimization) that helps economically distribute vision solutions leveraging AI.
QNAP provides OpenVINO™ Workflow Consolidation Tool to empower QNAP NAS as an Inference Server.
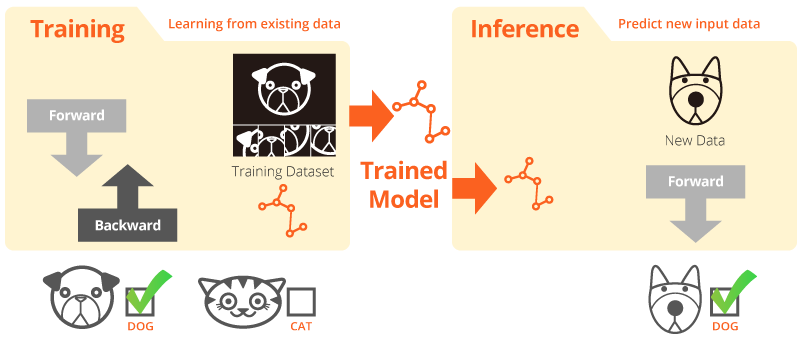
Training and Inference
“Training” is when the system learns from existing data. “Inference” is when a trained model is used to make useful predictions with real-world data.
Intel® Distribution of OpenVINO™ Toolkit
The OpenVINO™ toolkit helps to fast-track development of high-performance computer vision and deep learning into vision applications. It enables deep learning on hardware accelerators and easy heterogeneous execution across Intel® platforms, including CPU, GPU, FPGA and VPU. Major components include:
- The Intel® Deep Learning Deployment Toolkit (Model Optimizer and Inference Engine)
- Optimized functions for OpenCV* and OpenVX*
- Provides over 15 sample codes and pre-trained models for easy deployment

Source: Intel
Your AI Inference for computer vision, now faster!
Key benefits of using the OpenVINO™ Workflow Consolidation Tool (OWCT):
-
 Speed-up
Speed-up
-
 Optimization
Optimization
-
 GUI
GUI
-
Speed-up
The OpenVINO™ toolkit contains an open-source library that helps to reduce development time, and streamlines deep learning inference and deployment of vision-oriented solutions.
-
Optimization
The Model Optimizer converts trained models into an intermediate representation (IR) and performs basic optimizations for efficient inference.
-
GUI
OWCT uses a GUI that allows users to easily utilize OpenVINO™ capabilities, display visuals, and download the inference result.
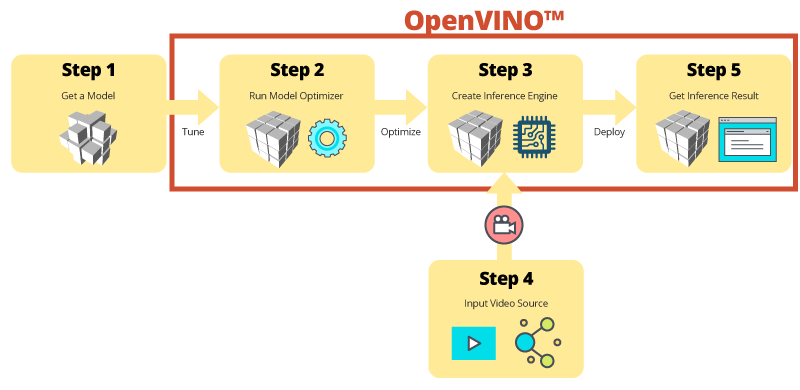
Step-by-step Inference with OWCT
The OWCT consolidates all the necessary features of OpenVINO™ to help you create the Inference Engine and review the inference results of the model. Simply follow the app wizard, and set things up in only a few steps!
Use pre-trained models to expedite development
Besides searching for, or training your own models, the OpenVINO™ toolkit also provides Intel® optimized pre-trained models in user applications, referred to as the Inference Engine.
-
The OpenVINO™ toolkit includes two sets of optimized models. You can add these models directly to your environment and accelerate your development.
Pre-trained models:
- Age & Gender Recognition
- Crossroad
- Head Position
- Security barriers
- Vehicle Feature Recognition
- … and more
-
Import your own trained models to leverage the optimization from Model Optimizer and Inference Engine, so in the end you can easily run inference for computer vision on current and future Intel® architectures to meet your AI needs. The OpenVINO™ toolkit works with pre-trained models that use Caffe or TensorFlow formats.
QNAP NAS as an Inference Server
OpenVINO™ toolkit extends workloads across Intel® hardware (including accelerators) and maximizes performance. When used with the OpenVINO™ Workflow Consolidation Tool, the Intel®-based QNAP NAS presents an ideal Inference Server that assists organizations in quickly building an inference system. Providing a model optimizer and inference engine, the OpenVINO™ toolkit is easy to use and flexible for high-performance, low-latency computer vision that improves deep learning inference. AI developers can deploy trained models on a QNAP NAS for inference, and install hardware accelerators based on Intel® platforms to achieve optimal performance for running inference.

Easy-to-manage Inference Engine
-
Upload a video file
-
Download inference result
Improved performance with accelerator cards
The OpenVINO™ toolkit supports heterogeneous execution across computer vision accelerators (CPU, GPU, FPGA, and VPU) using a common API for device-specific optimization.
-
AcceleratorFPGA
- Intel® Arria® 10 GX 1150 FPGA
- PCIe 3.0 x8
- Low profile, half size, double slots

-
AcceleratorVPU
- Intel® Movidius™ solution
- 8x Myriad™ X VPU
- PCIe 2.0 x4
- Low profile, half size, single slot


TVS-x72XU Series |

TVS-x72XT Series |

TS-2888X |
|---|---|---|
Note:
- QTS 4.4.0 (or later) and OWCT v1.1.0 are required for the QNAP NAS.
- To use FPGA card computing on the QNAP NAS, the VM pass-through function will be disabled. To avoid potential data loss, make sure that all ongoing NAS tasks are finished before restarting.
- Complete supported models (Check OWCT Release Note)
- TVS-x72XT: CPU, iGD, VPU (Note: TVS-472XT is not supported)
- TVS-x72XU: CPU, iGD, FPGA, VPU
- TS-x82: CPU, iGD, FPGA, VPU
- TS-x83: CPU, FPGA, VPU
- TS-x85: CPU, FPGA, VPU
- TS-x88: CPU, FPGA, VPU
- TS-x89U: CPU, FPGA, VPU
OpenVINO and the OpenVINO logo are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries.





